


Demystifying ChatGPT
Reverse engineering the OpenAI chat demo to understand the next-generation chatbot's intrinsic behavior better.


Everyone not living under a rock should be well aware of all the buzz related to OpenAI just released ChatGPT application. It's near-human response accuracy and conversation capabilities are astonishing and opened a wide range of possible applications.
One of the critical features of ChatGPT is its ability to generate relevant and coherent responses within a given conversation. This is achieved through combining techniques, including deep learning, unsupervised learning, and fine-tuning large amounts of conversational data.
In addition to its ability to generate responses, ChatGPT also understands and interprets a conversation's context. This allows it to create appropriate responses for the situation, making it more effective at maintaining a natural and flowing conversation.
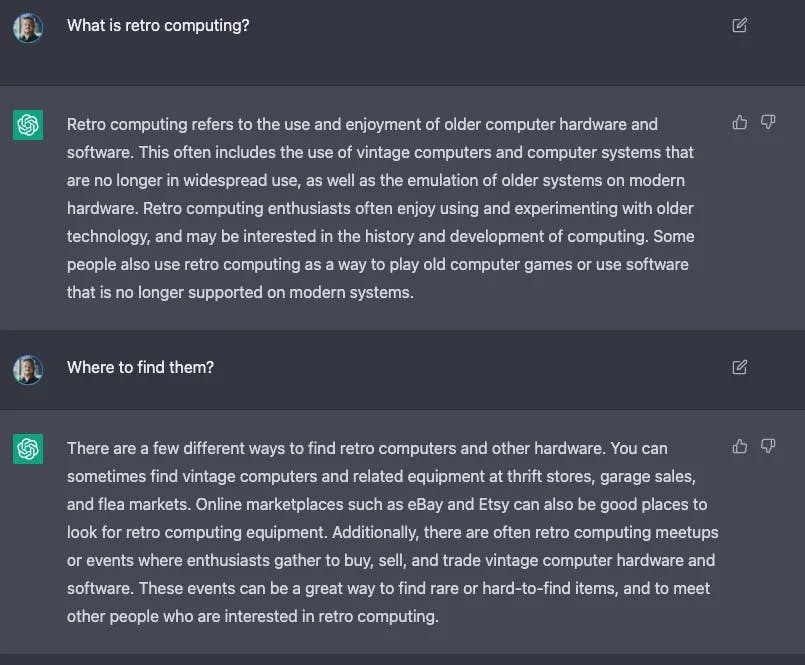
Overall, ChatGPT is a powerful and versatile tool that has the potential to revolutionize the way we interact with machines. Combining deep learning, unsupervised learning, and fine-tuning large amounts of data can generate human-like responses and help understand the context of a conversation. This makes it a valuable tool for many applications, from customer service to language translation.
Unfortunately, no API is available.
Almost every developer is looking for APIs to interact and integrate chatGPT into their application. Unfortunately, OpenAPI does not offer a public API to be used through their SDK or a simple HTTP interface, as the model explains upon request.
Using chatGPT through an SDK or directly calling remote APIs would open a whole set of applications, enabling developers to integrate its astonishing capabilities into every app.
In this article, reverse engineering of the private APIs offers a better understanding of chatGPT behavior and some insights into its functioning under the hood.
Reverse engineering the demo app.
Disclaimer: This article is for the sole purpose of providing a better understanding of chatGPT intrinsics, while we wait for OpenAI to release full documentation and support through their official SDKs with relative billing. Please be careful because APIs could change without notice because they are not public and/or your account could be banned for improper service usage. If you use the results of this analysis do it at your own risk.
ChatGPT demo app is a web application released in HTML, CSS, and Javascript. Its code is fully minified and chunked using Webpack, but with Chrome Inspector is relatively easy to track remote network calls and identity some exciting facts.
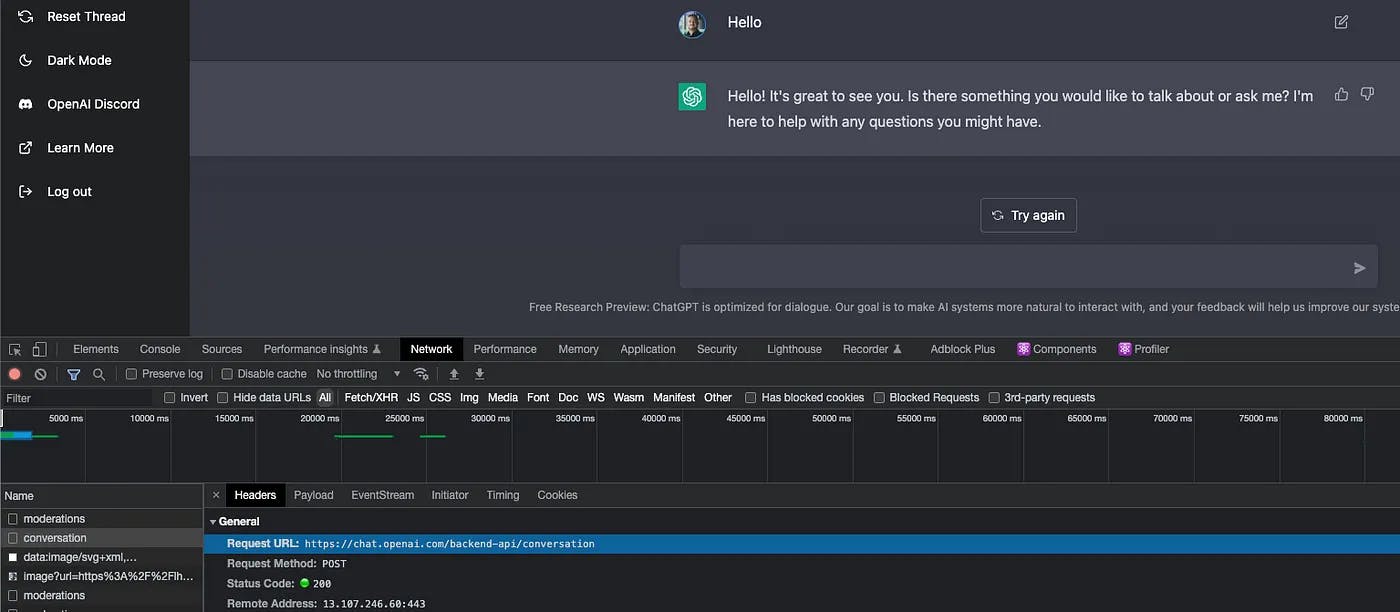
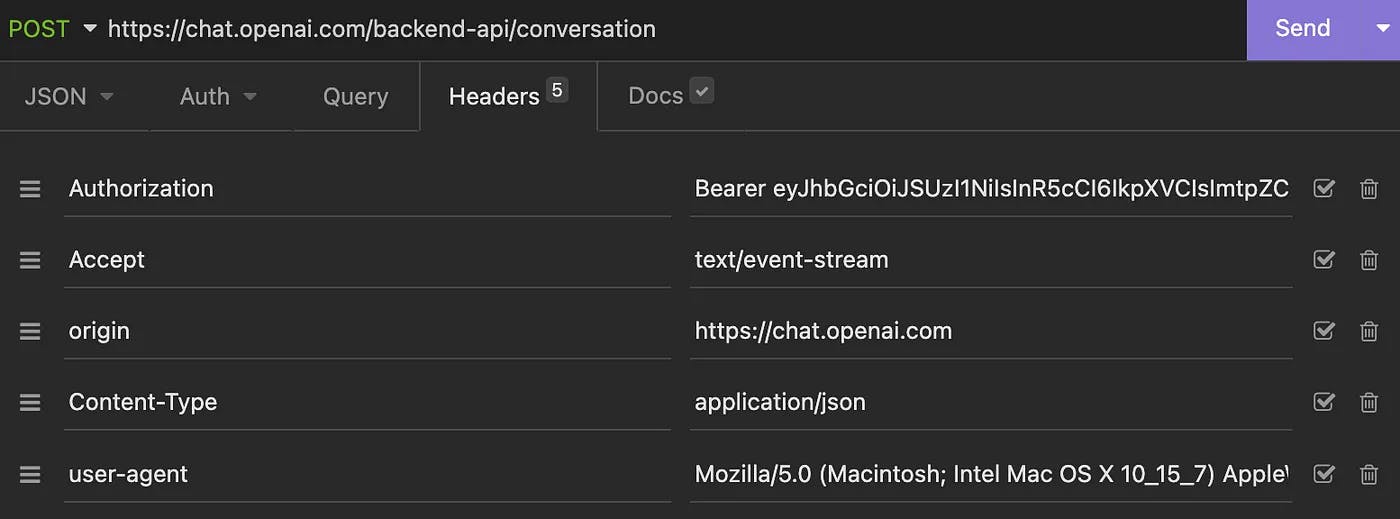
After the login, three endpoints are invoked for every action a user does and provide support for conversation management.
Invoking these endpoints from any REST client allows interaction with the chat model, like the demo app. Much work is done through HTTP headers, which pass parameters to the stateless backend, allowing to recover session and user state. To ensure chat services are accessed through a web app, OpenAI must specify a user-agent header, which we must set appropriately in our HTTP client to a valid value; otherwise, our requests will be rejected. In our case, we used Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko), Chrome/108.0.0.0 Safari/537.36 to emulate a Chrome user agent on a Mac OSX. This header must be set in any request.
Obtaining a session token
Once the username is known after login, the first step is to obtain a session object from its relative endpoint (https://chat.openai.com/api/auth/session). This is achieved through a call that returns the following payload:
{
"user": {
"id": "user-myuserid",
"name": "Luca Bianchi",
"email": "luca.bianchi@myemail.com",
"image": "https://path/to/user/image",
"picture": "https://path/to/profile/picture",
"groups": [
"codex",
"sunset-search-endpoint",
"sunset-answers-endpoint",
"sunset-classifications-endpoint"
],
"features": []
},
"expires": "2023-01-05T23:10:33.681Z",
"accessToken": "eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCIsImtpZCI6Ik1UaEVOVUpHTkVNMVFURTRNMEZCTWpkQ05UZzVNRFUxUlRVd1FVSkRNRU13UmtGRVFrRXpSZyJ9.eyJodHRwczovL2FwaS5vcGVuYWkuY29tL3Byb2ZpbGUiOnsiZW1haWwiOiJsdWNhLmJpYW5jaGlAbmVvc3BlcmllbmNlLmNvbSIsImVtYWlsX3ZlcmlmaWVkIjp0cnVlLCJnZW9pcF9jb3VudHJ5IjoiVVMifSwiaHR0cHM6Ly9hcGkub3BlbmFpLmNvbS9hdXRoIjp7InVzZXJfaWQiOiJ1c2VyLTdYVW1QSWFuYXdBYkNYRFNJSzQ1YVlVTyJ9LCJpc3MiOiJodHRwczovL2F1dGgwLm9wZW5haS5jb20vIiwic3ViIjoiZ29vZ2xlLW9hdXRoMnwxMDA0Nzk5NDI1MTA3MTQ3NzQwNTciLCJhdWQiOlsiaHR0cHM6Ly9hcGkub3BlbmFpLmNvbS92MSIsImh0dHBzOi8vb3BlbmFpLmF1dGgwLmNvbS91c2VyaW5mbyJdLCJpYXQiOjE2NzAzNjc5ODQsImV4cCI6MTY3MDQ1NDM4NCwiYXpwIjoiVGRKSWNiZTE2V29USHROOTVueXl3aDVFNHlPbzZJdEciLCJzY29wZSI6Im9wZxlIG1vZGVsLnJlYWQgbW9kZWwucmVxdWVzdCBvcmdhbml6YXRpb2VzcyJ9.cKNnpAPSVjcqFblcuOORSWuU8mPv4_sazTIuYUmlYHJN_DYD16U5fkKSKG8rQNSmkeDyssPIL1ZhEokSvQHaaqORAe0hZAsynhA5qaUzdVG4XBRcnuM5BE4YLLDiQzfrrezMLybAu-I6ktCGHezQeRP1VC5jR0mwsPLaUwZOoBM4oj4drFHW8K73gjaKGcHlZmRpD2EinEy_ofQEAz8LYZgQXpyzZ0U9gsG2DDctqsuh-CRbOXlQ5Xl2diD6IiMhPBxNdI"
}
An access token is also returned with meaningful user information lasting one month. The standard JWT token can be decoded to extract user information, the identity provider (basically Google through Auth0), and authorized scopes for user data.
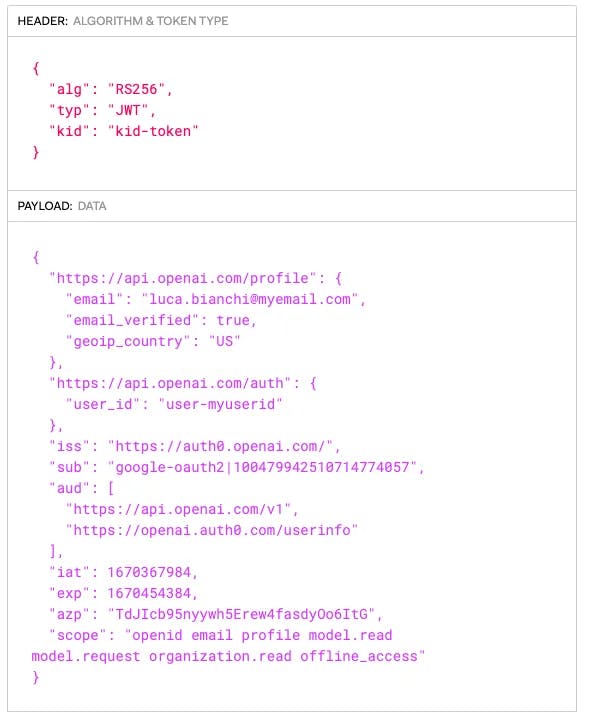
Please refer to the official documentation for more information about the JWT standard and its usage in the OAuth2 workflow. For our purposes, it is enough to get the token we will use in our Authorization HTTP header for the following calls.
Start the conversation
We can invoke the conversation endpoint (chat.openai.com/backend-api/conversation) using the obtained token with the following parameters. Interestingly, the first message requires setting the action attribute as "variant" and then an array of messages.
{
"action": "variant",
"messages": [
{
"id": "b866650c-4797-4fc9-91dc-962af79ff369",
"role": "user",
"content": {
"content_type": "text",
"parts": [
"Who are you?"
]
}
}
],
"model": "text-davinci-002-render"
}
The response to this payload is a data stream containing the whole set of text tokens building the response. Streams are sent incrementally and terminated by a [DONE] sequence.
To provide an example, the first response in the stream is
data:
{
"message": {
"id": "a49b7544-f0eb-43eb-9e56-f28b2961bf19",
"role": "assistant",
"user": null,
"create_time": null,
"update_time": null,
"content": {
"content_type": "text",
"parts": []
},
"end_turn": null,
"weight": 1.0,
"metadata": {},
"recipient": "all"
},
"conversation_id": "09794ccf-2690-449a-86a3-2e5be51e9b6b",
"error": null
}
While the last chunk of the stream is
data:
{
"message":{
"id":"a49b7544-f0eb-43eb-9e56-f28b2961bf19",
"role":"assistant",
"user":null,
"create_time":null,
"update_time":null,
"content":{
"content_type":"text",
"parts":[
"I am Assistant, a large language model trained by OpenAI. My primary function is to assist users in generating human-like text based on the input provided by the user. I am not a real person, but a program designed to simulate intelligent conversation."
]
},
"end_turn":null,
"weight":1.0,
"metadata":{
},
"recipient":"all"
},
"conversation_id":"09794ccf-2690-449a-86a3-2e5be51e9b6b",
"error":null
}
Every chunk is sent back as a stringified JSON containing text data and a conversation_id, which helps handle the conversation follow-up.
Continuing conversation
Invoking the same endpoint with the "next" action and two follow-up attributes ensures the conversation context is maintained between different calls. The two fundamental parameters are conversation_id and parent_message_id. The first ensures all the messages belong to the same conversation, while the latter supports message ordering.
{
"action": "next",
"messages": [
{
"id": "0137111d-8034-43c1-b535-96dfe4270c95",
"role": "user",
"content": {
"content_type": "text",
"parts": [
"What is a grizzly?"
]
}
}
],
"conversation_id": "15ad362d-e9f9-47bc-a4d2-c1e398466dc1",
"parent_message_id": "eee9d792-ec2b-44d2-8835-e2c578bab585",
"model": "text-davinci-002-render"
}
One of the most exciting attributes of the payload is a model attribute that points to text-davinci-002-render, suggesting it is using the OpenAI davinci-002 model under the hood. This model has been fine-tuned to provide chatGPT-specific information and moderate results.
Moderation monitoring is also achieved through the moderation (https://chat.openai.com/backend-api/moderations) endpoint, which receives the whole chat text every time a new sentence is appended (either by the model or the user) and returns feedback about whether the conversation contains sensitive information or not.
Where to go from here?
The release of the ChatGPT demo app gained unprecedented interest from the vast user community. Many people started discussing the power of domain-free conversation enabled by such models. However, even if no API had been released, the developer community started imagining how a possible integration could work. In such a context, we could reasonably expect the rise of conversational agents into several real-world applications shortly. In the meantime, some proofs-of-concept can be developed leveraging existing API, as discussed in this article.