


Serverless Big Data: lessons learned building a data ingestion pipeline on Amazon Web Services


In recent years the amount of data generated by brands increased dramatically, thanks to affordable storage costs and faster internet connections. In this article, we explore the advantages serverless technologies offer when dealing with a large amount of data and the common pitfalls of these architectures. We will outline tips everyone should figure out before starting their next big data project.
Talking about big data is not easy because we have to define what we mean by “big.” To make the discussion more practical, consider a real use case: we must build a service to ingest event data from browsers. Users generate events when navigating a website that has our javascript library installed. We aim to monitor every mouse/touch event on a given homepage. Then our pipeline feeds this set of data into a machine-learning model. The outcome is a set of navigation patterns and a better classification against personality traits to empower 1:1 personalization.
Our topic matters because each event is structured as a lightweight and straightforward JSON object, and the client-side library will deliver them in small batches to reduce the frequency of data sent to our service. The JSON structure looks like the following:
{
"eventType":"the type of the event",
"browser": "browser engine version",
"timestamp": "2019-11-15 18:05:00Z"
"path":"urls of the current page",
"target": "reference to the DOM element that received the event",
"data": {
// an hashmap containing event specific data
}
}
In other words, you could think of a supercharged version of Google Analytics, producing tens of events per user per second. You can quickly ramp up to millions of events in just a few days. Because we want to adopt a SaaS model, the architecture has to handle such volume for potentially every Neosperience customer.
In terms of scale, a single medium-sized customer could easily produce 25–30GB of data per week.
Let’s dig into the white rabbit hole.
Serverless architectures are a perfect fit for such use cases because they intrinsically scale up and down automatically without (almost) any ops intervention. Also, you can cheaply deploy testing/staging environments without over-provisioning or paying for a fixed amount of unused resources by the hour. Here I’d like to share some lessons learned that could help you avoid common pitfalls in your next project. We will consider three different dimensions: persistence, ingestion, and analysis. AWS offers various services to address these tasks, each one built for a specific purpose (remember the Cathedral and the Bazaar model). The tricky part is choosing wisely the most suited for a given use case because changing your mind later has a cost in a Big Data world.
Persistence
TL, DR: always stay on the safe side and use S3 as flexible persistence for any kind of Big Data. DynamoDB is a good choice too but needs to plan a couple of things.
Choosing the right storage for your data is the most vital task to select at the beginning. It is even more relevant when you’re pushing gigabytes of items daily into your storage. A poor choice will result in your team having to figure out how to move millions of records around, with increased costs in data access and people wasting days, which translates into an even stronger economic impact.
Any managed service could do the trick because their scalability is not on your team's duties. For this reason, I strongly discourage using for these purposes services you have to scale up manually (even if this is a task that is accomplished with a single click in the console). At the time of writing, this excludes Amazon DocumentDB and Amazon Elasticsearch as viable options. It doesn’t mean we cannot use them at all, but they are not the best tool in your belt to receive data from clients. We are using them later in our pipeline for data storage and consolidated views, respectively.
Exploring managed persistence brings us to consider Aurora Serverless, Amazon DynamoDB, and Amazon S3.
Amazon Aurora Serverless is a great tool for handling unpredictable loads that can vary over time, suited for a relational database. It is completely new because it challenges the CAP theorem and provides cost-effective data storage. Ingested events, however, have a flat structure and grow in volume; this means we miss all the benefits of Aurora while facing considerable costs. Moreover, Aurora requires seconds to scale up the cluster, thus making this too slow for spikes in ingested events.
Amazon DynamoDB is a good fit for high-volume data and, thanks to the on-demand capacity released in 2018, can scale up as fast as your data coming into the pipeline. It’s one of the best solutions AWS can offer, tested by dozens of Black Fridays on Amazon.com. If data ingestion is fast and occurs at a competitive price, some fine-tuning is required to pull data from DynamoDB. AWS did not design DynamoDB for analytical purposes. The supported query language can’t perform complex queries on data.
Performing a full scan of the table is not the best practice. It requires considerable time (even with proper indexing of your data). Moreover, it bursts your capacity units. The result is additional costs of up to thousands of dollars for a single full scan. Also, there is a limit of 1MB on the amount of data returned from a single scan operation that would require you to concatenate multiple API calls using LastEvaluatedKey, making things more complicated following this approach. It’s not DynamoDB's fault; your architecture uses it for the wrong purpose.
If you still want to use DynamoDB to extract data, you can mitigate this drawback setting up global secondary indexes to map your desired extractions. There is a soft limit of 20 GSI. Nevertheless, be sure to define them ahead of time and consider costs. Any new global index on an existing table means Dynamo has to scan all the Partition Keys of the source to fill the underlying reference table. Consider that, in any case, writing to a table with a GSI increases costs due to the capacity consumed to update the underlying table from the base table.
A widespread pattern is using DynamoDB as a cache database, leveraging its incredible resiliency to traffic spikes and pull data out at a lower frequency soon after writing. It can easily be achieved using DynamoDB streams to feed a Lambda function with records after a certain time. The result is a common fan-out scenario where stream records number (thus event frequency) can be decided independently from ingestion frequency. Such a Lambda function could easily persist data into a different store.

Amazon S3 is often considered the best choice for either first or second-level storage due to its high flexibility in accepting practically every structured or unstructured data. Writing can be done with a Lambda function or streams, flushing data directly to S3. Moreover, reading data from S3 can be achieved through some services that rely on the object store, such as AWS Glue and Amazon Athena. S3 was our choice, too, and we’ll discuss how it supports ingestion and data analysis throughout the article.

Takeaways
Aurora is a great database, fully serverless, but up/down scalability does not happen within a second, thus if you use it as first-level storage, it quickly becomes a bottleneck.
DynamoDB is a better choice, it can ingest data almost at any frequency. Pulling data out of DDB isn’t hard, but it depends on the access patterns you have defined and optimized. If you’re using it as the first-level cache, remember to always set up streams and eventual GSIs before inserting the first event.
S3 is my preferred choice due to its extremely high flexibility in supporting any data structure. Data partitions have an impact on later phases
Ingestion
TL, DR: always expose a REST endpoint to your client. API Gateway is the perfect fit. Lambda is doomed by a cold start that affects both the first run and new containers. Consider Gateway proxying other AWS services. Prefer Firehose to push data directly into S3.
A widely accepted best practice in software development is to adopt standard interfaces to make integration and usage faster for both internal and external developers. Since we’d like to write modern apps, our service has to offer a REST interface with standard OAuth2 authentication. As usual, AWS has our back covered with Amazon API Gateway. We can provide a standard layer for our API.
The most common way to use API Gateway is with proxy integration to AWS Lambda, which could be an option for our use case. Unfortunately, Lambda functions present cold start issues when AWS has to instantiate a new runtime. It is a frequently misunderstood issue because its name suggests it only impacts the start of our service (which, for this use case, would be irrelevant). Sadly, cold start affects any new instantiated runtime, which frequently happens when your request rate is ramping up quickly. Keeping Lambda payload small should be a mantra for every serverless developer, as well as in-depth knowledge of cold start dynamics. Still, it is not enough to face a massive number of concurrent requests per second (sometimes more than a few hundred).
Luckily for us, API Gateway has an often unknown feature that can save our day: AWS service proxy. Using a Velocity template, we can map REST API params to any HTTP service in our cloud account. It means we can also expose AWS resource methods directly with no need for function code.
Velocity templates are not the most comfortable code in the world to write and debug but do their job, allowing them to expose a managed service with a standard interface. In this use case, I suggest leveraging the capabilities of Amazon Kinesis Data Firehose, which is entirely serverless (compared to Amazon Kinesis Data Streams, which requires you to manage scalability). Firehose can flush your data directly into an S3 bucket with a default or custom key schema. Moreover, to fit your need, if you have to mangle some data, a Lambda function can be used as a transform from the queue (so it is invoked at a lower frequency) right before sending data to storage.
Firehose has a hard limit of 500 records per call and a soft limit of 4000 records per second. These should fit pretty much any use case that can occur, but if you exceed them, I would suggest taking into consideration deploying a Lambda function et Edge on Cloudfront to receive and store a batch of data asynchronously.

Once your data is safely and cheaply ingested into S3, it’s time to extract meaningful information.
Takeaways
Using proprietary interfaces, even from AWS, is a bad practice. Stick with standard REST endpoints.
Kinesis Data Firehose is preferable over Kinesis Data Streams because it handles transparently up to 500 items/second. If you need more throughput, use Lambda @ Edge to push into a pool of streams.
If API Gateway is invoking Lambda, cold start matters. It does not happen just when the first event comes but any time a new Lambda runtime is initialized.
To avoid cold starts, consider using API Gateway as a proxy to Kinesis (or Dynamo). I am not a big fan of Velocity templates, but this could save your day.
Analysis
TL, DR: Amazon Athena is the best choice to query your data on S3, its performance scale is not linearly with cost. Adding AWS Glue could allow data to transform into columnar parquet format with a considerable saving in storage and query costs.
Once we pushed to S3, we have some tools at our convenience to analyze our data and extract meaningful insight to be used in a machine learning model.
The best tool in your belt to run queries on stored data is Amazon Athena, which comes with Presto SQL support and no need to index data (which is a significant saving in time and costs when you have terabytes to process). SQL interface is compelling and supports searches of any complexity. Nested queries deserve a special mention because they allow grouping data in sub-domains, then queried again.
Athena would suffice for every task we need to accomplish on data, but having full bloat stored on S3 is not the most cost-effective approach. A nice add-on is to leverage AWS Glue ETL capabilities to transform data into a columnar format. Athena supports Apache Parquet with no additional configuration or code needed. Consider that things get more complicated when using Glue because, by default, it requires data partitioned in Hive style. However, you can define a custom partitioning schema, but it requires additional work, so configure Firehose wisely at the beginning and avoid all the hassle.
One additional suggestion is consolidating Athena’s outcome into real-time coarse-grained results in an Amazon Elasticsearch domain. It provides the best of two worlds: Athena performs massive queries on stored data and consolidates results into Elasticsearch which acts as persistence to client apps searching fine-grained data. One of the most recurring concerns with Elasticsearch is about scaling its domain, an operation that requires minutes, thus making this infeasible to use it as our primary storage. But it works after Athena crunched our dataset a bit, and data dimensionality is more predictable upfront (we’re working at a lower frequency).
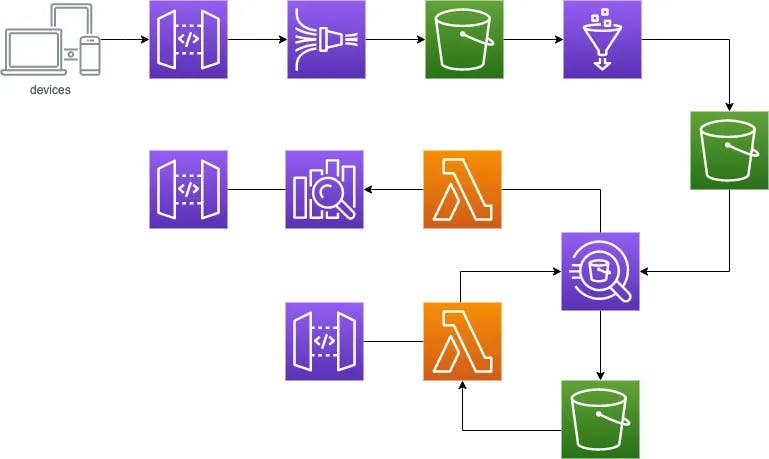
Takeaways
AWS Glue could scrape your data and convert it to Parquet format, reducing storage footprint and costs. S3 keys name matters for automatic partitioning. If you miss it, you’ll have to write code to handle custom schema. Stick with defaults and save time.
Amazon Athena does a great job scanning your data in just a few seconds. Its built-in support for SQL is mighty
Consider consolidating Athena query results in an Elasticsearch cluster to be used as a view for real-time queries
Where to go from here
In this article, we propose an approach to address big data coming from user-generated events in an entirely serverless manner. The resulting architecture is scalable and efficient to allow event ingestion. Here we outline common pitfalls and lessons learned building a Serverless SaaS product on Amazon Web Services.